B-Tree & Index
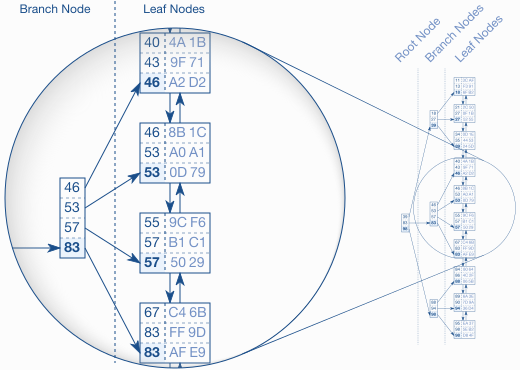
B-Tree
Self-balancing search tree로 정렬된 데이터를 유지하며 검색, 삽입, 삭제 연산 시 시간 복잡도는 로그 시간(log2N)이다. Real MySQL에서 B-트리의 B는 Balanced라고 명시돼 있으나, 정작 이를 창안한 사람들은 B가 무엇인지 이야기한 적이 없다.
창시자들은 "B-트리에서 B가 뭔지 고민하면 할수록 B-트리를 더 잘 이해할 수 있을 것이다."라고 설명했다.
B-트리는 Binary Tree와 달리 한 노드가 두 개 이상의 자식 노드를 가질 수 있다. Binary Tree의 연산 시간 복잡도는 높이에 종속되며 편향 트리라면 최악의 시간 복잡도가 O(n)이지만, B-Tree는 균형 트리라서 일정하게 O(log n)이다.
메모리에 적재할 수 없는 크기의 데이터는 디스크에 적재시켜 블록(페이지) 형태로 읽어와야 한다. 이때 디스크 입출력(seek time + latency + transfer time: 대부분 디스크 헤더 회전 비용)은 시간이 많이 소요되므로, B-Tree는 디스크 접근 횟수를 줄이기 위해 사용된다. 일반적인 트리들의 연산(검색, 삽입, 삭제, max, min 등)은 O(h)(h: height)지만, B-Tree는 한 노드에 가능한 많은 key들을 포함시켜서 트리의 높이를 낮춘다. 그로 인해, Fat Tree라고도 부른다.
자식 노드를 M개까지 가질 수 있는 B-Tree를 M차(order) B-Tree라고 부른다. 그러면 한 노드 안에 key는 M-1개가 있을 것이다. B-Tree에서 모든 브랜치 노드는 최소 ⌈m/2⌉ 개의 자식 노드가 있어야 한다. 그 이유는 불필요한 공간 낭비를 줄이기 위함이다. 즉, 노드가 존재하려면 최소 ⌈m/2⌉ 개의 자식 노드가 있고 ⌈m/2⌉-1개의 키 값을 가져야 한다. 하지만 이 또한 학계에서 정한 값일 뿐, 실제로는 B-Tree 구현마다 다양한 것으로 보인다.

만일, 인덱스가 없는 컬럼에 대해 where 절을 사용한다면 풀 테이블 스캔을 하며 조건과 일치하는 레코드들을 걸러내서 반환한다. 그래서 where 조건 절에 자주 명시되는 컬럼은 인덱스를 적용하는 것이 효율적이다.
인덱스가 항상 성능에 좋은 건 아니다. 인덱스도 물리적인 공간을 차지하고 생성될 때마다 정렬된 상태를 유지하기 위한 오버헤드가 발생한다. 그래서 삭제할 때도 실제로는 인덱스를 지우지 않고 '사용하지 않음' 처리만 하여 정렬을 피한다. 또한, 쿼리 옵티마이저는 여러 인덱스들 중 어떤 걸 택해야 저비용의, 최적화된 방식으로 쿼리를 실행할지 판단해야 한다.
Clustered Index
이는 데이터가 위치한 디스크 파일과 병치된 인덱스 종류로 테이블 당 하나만 가질 수 있다. 그 이유는 클러스터드 인덱스 기준으로 레코드들의 물리적 위치를 결정되기 때문이다. 이 인덱스는 B-Tree 구조로 인덱스와 데이터가 같은 물리적 공간(디스크 블록)에 위치하므로 리프 노드들이 디스크 상 데이터의 물리적 위치를 가리킨다. 그 결과, 실제 데이터도 인덱스처럼 정렬하여 디스크 IO가 빨라질 수 있다.
데이터는 수천에서 수백만개의 디스크/데이터 블록에 저장된다. 이때 데이터가 저장된 블록끼리 인접할 필요는 없다. 데이터 블록 이동은 OS 권한이지만, 인덱스들은 키에 따라 정렬해놓을 수는 있다. 말이 어려우므로, 그림으로 이해한다.
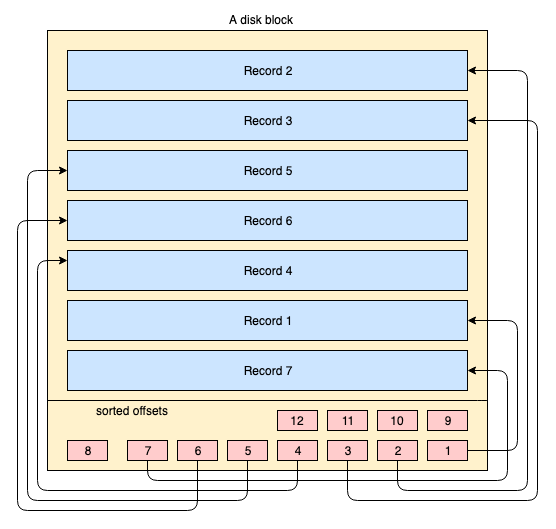
- 노란 블록은 디스크 블록 / 데이터 블록이다.
- 파란 블록은 블록 내 저장된 데이터(레코드)이다.
- 하단 영역은 블록의 인덱스를 나타내며, 빨간 블록들은 각 레코드 별 offset(위치)를 가리키는 포인터 역할을 하며 특정 key에 따라 정렬된다.
블록 안의 레코드들은 물리적인 순서가 없고, 새로운 레코드가 삽입될 때마다 단순히 다음 빈 공간만 채운다. 기존 레코드가 수정될 경우, OS가 이 레코드의 위치를 그대로 둘지 옮길지 결정한다. 대다수 블로그 글들은 레코드 위치를 정렬하는 것으로 설명하는데 이건 잘못된 설명인 것 같다. 즉, 레코드의 순서는 오로지 OS의 권한이며 순서에 어떤 의미가 없다. 디스크 페이지(블록) 내 인덱스들은 레코드 오프셋를 가리키는 포인터를 가지며 이들은 키 기준으로 정렬되어 있다. 인덱스는 레코드가 삽입 또는 수정될 때마다 그에 따라 바뀐다.
클러스터드 인덱스를 통해 레코드를 접근하는 것이 빠른 이유는 인덱스를 탐색하다 리프 노드에서 즉시 레코드를 포함한 페이지(=블록)를 찾아갈 수 있기 때문이다. 인덱스 레코드와 실제 데이터 레코드를 개별적인 페이지에 위치하는 방식에 비해 디스크 I/O가 줄어들 수도 있다.
인덱스와 데이터를 동일한 디스크 블록에 위치하는 클러스터드 인덱스는 데이터 읽기 속도를 향상시킬 수 있다. 디스크는 블록 단위로 입출력하므로 디스크로부터 데이터를 읽을 경우, 데이터베이스 시스템은 데이터가 포함된 디스크 블록 전체를 fetch(가져오기)한다. 간단한 예시로, where 절에 범위가 명시된 select 쿼리를 수행할 때 클러스터드 인덱스의 역할을 알아보겠다. 아래 SQL 문을 실행하는 경우를 예로 설명을 하자면,
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
위 쿼리가 요청되면 디스크로부터 데이터 블록을 메모리로 읽어온다. 만일 읽어온 디스크 블록에 phone_no가 9010000000에서 9030000000 사이에 속하는 레코드들이 존재한다면 요청한 범위에 해당하는 레코드들이 모두 블록에 존재하므로 다른 블록을 추가로 읽어올 필요가 없다. 이어서 다음 쿼리를 추가로 실행한다면,
SELECT * FROM index_demo WHERE phone_no > '9015000000' AND phone_no < '9019000000'디스크를 접근할 필요가 없다. 이유인즉슨, 해당 범위의 레코드들을 가진 데이터 블록이 이전 쿼리에서 이미 읽혀져 메모리 상의 Buffer Pool에 존재하기 때문이다. 정리하면 클러스터드 인덱스는 연관있는 데이터끼리 최대한 같은 데이터 블록에 위치시켜 디스크 IO를 줄이는 효과로 DBMS의 성능을 높인다. 사용자가 올바른 PK를 클러스터드 인덱스로까지 활용한다면 데이터를 매우 빠르게 읽을 수 있을 것이다. 이때 PK가 숫자가 아니라면 읽기/쓰기 속도가 느려질 수 있다. 클러스터드 인덱스를 명시하지 않으면 자동으로 PK로 설정되지만 후보키를 활용해도 된다. 만약, PK가 여러 테이블들에 대한 외부키의 조합으로 구성된다면 쓰기 연산 시 disk shuffle 오버헤드 때문에, 다른 후보키를 클러스터드 인덱스로 사용하는 것이 나을 수 있다.
반면, InnoDB 엔진은 클러스터드 인덱스를 사용자가 직접 정할 수 없고 엔진이 직접 결정한다. PK가 있다면 이를 클러스터드 인덱스로 설정하므로 레코드들은 PK와 함께 위치한다. 하지만 PK가 없는 테이블이라면 엔진이 적절한 후보키를 PK로 스스로 선정한다. 이때 후보키를 만족하는 속성 집합이 없다면 비가시적인(non-visible) 컬럼을 추가하여 레코드마다 삽입 순서에 따라 auto-increment하는 번호를 기입하며 이를 클러스터드 인덱스로 사용한다. MySQL 공식 문서에 의하면, clustered index는 primary index와 일반적으로 동의어라고 한다. 하지만 반드시 일치하는 것은 아니다.
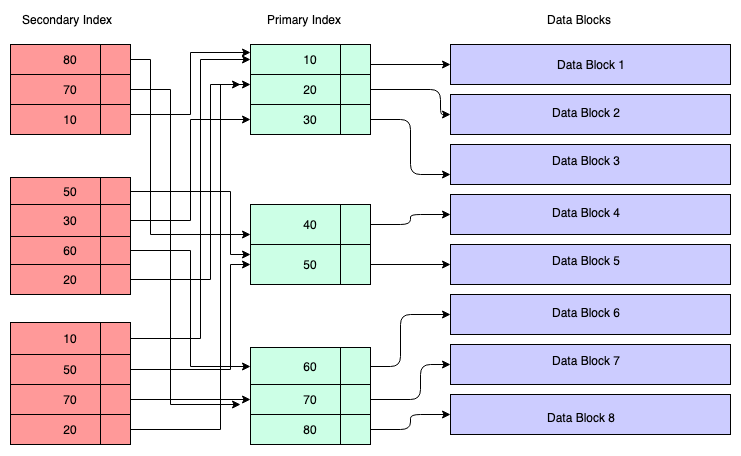
Secondary Index
Clustered Index가 아닌 모든 인덱스를 Secondary Index(이하 세컨더리 인덱스)라 부른다. 클러스터드 인덱스와 달리 레코드들의 물리적인 위치를 결정하는데 영향은 없다. PK가 아닌 컬럼에 대해 where 절이나 order by 절을 자주 사용한다면 그 컬럼에 Secondary Index를 적용하는 것이 효율적이다.
아래 그림은 지금까지 나온 모든 내용의 구조를 나타낸다. 세컨더리 인덱스 또한 인덱스 생성시 정한 키에 대한 B+-Tree 구조를 유지될 수 있다. 세컨더리 인덱스의 리프 노드는 클러스터드(Primary) 인덱스를 참조한다. 즉, 세컨더리 인덱스를 통해 데이터를 읽으면, 두 개의 B+-Tree를 거쳐야 한다.
B-트리의 특성(m차 B-트리일 때)
- 모든 노드는 최대 m개의 자식 노드를 가진다.
- 각 내부(브랜치) 노드는 최소 ⌈m/2⌉ 개의 자식을 가진다. 이를 이행하기 위해 자식 노드가 ⌈m/2⌉ 보다 적어지는 경우 노드를 split/merge한다.
- 모든 내부 노드는 최소 두 개의 자식 노드를 가진다. 반면, 루트 노드는 최소 자식 수 값이 적용되지 않으며 자식 노드가 없을 수도 있다.
- 모든 리프 노드는 같은 높이(레벨)에 위치한다. 즉, 균형 트리이다.
- k개의 자식 노드를 갖는 모든 non-leaf 노드는 k-1개의 키 값을 가진다.
- B-Tree는 minimum degree(최소 차수)라는 속성 t를 가지며 t는 디스크 블록 크기에 의해 결정된다.
(앞의 m과 t는 다르다.) - 노드의 키들은 오름차순으로 정렬되며 k1과 k2 사이에 위치한 자식 노드는 k1과 k2 사이의 키 값들을 가진다.
- B-Tree에서 노드의 삽입은 오직 리프 노드에서만 일어난다.
- B-트리는 다른 이진 트리가 아래로 늘어나고 아래부터 줄어드는 것과 달리 위로 늘어나고 위에서부터 줄어든다.
- 모든 노드(루트 포함)는 최대 2*t-1개의 키를 가진다.