Programming
Kafka 왜 쓸까?
appendonly
2024. 2. 5. 04:04

Kafka가 뭘까?
카프카는 스트리밍 데이터를 실시간으로 받고 처리하는데 특화된 분산 데이터 저장소이다. 스트리밍 데이터란 수천개의 데이터 원천들로부터 지속적으로 생성되는 데이터다. 카프카와 같은 스트리밍 플랫폼은 이러한 대량으로 유입되는 데이터를 순서대로 처리할 능력이 요구된다.
카프카는 사용자에게 세 가지 기능을 제공한다:
1. 스트림 데이터의 publish 및 subscribe
2. 생성된 순으로 레코드(데이터) 스트림을 효율적으로 저장
3. 레코드들의 스트림을 실시간 처리
카프카는 실시간 스트리밍 데이터 파이프라인과 애플리케이션을 만들 때 활용된다. 메세징, 저장과 스트림 처리 기능을 제공하여 과거와 실시간 데이터 둘 다 유지하며 분석할 수 있다.
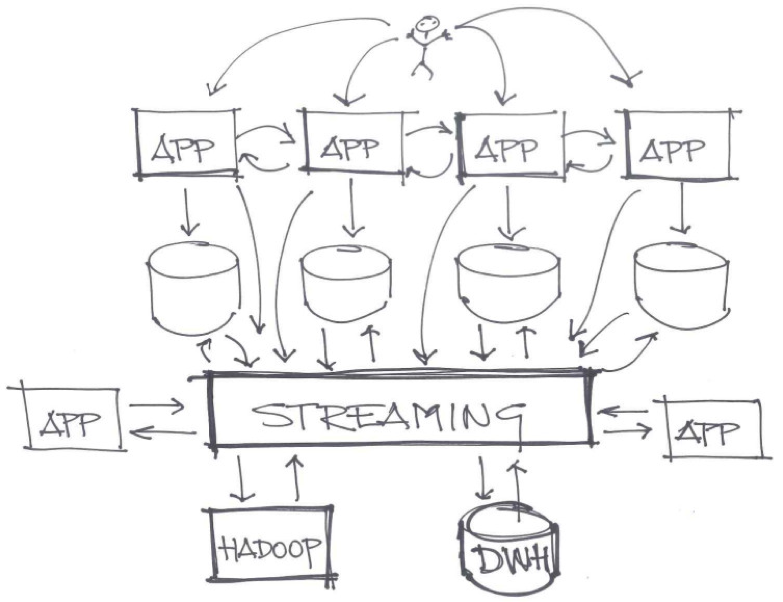
Kafka가 왜 필요할까?
데이터 파이프라인과 메세지 큐잉: 카프카는 스트리밍 데이터를 수집, 저장, 분산시키는 역할을 하므로 데이터의 중심지라고 볼 수 있다. 발행(Publish)과 구독(Subscribe) 모델을 통해 이종 시스템 간 안정적인 통합을 제공한다.
확장성 및 높은 처리율: 카프카는 대규모 데이터 스트림을 분산 처리하기 위해 브로커 또는 서버를 추가하는 수평적 확장이 가능하다. 이로써, 로그 집계, 이벤트 처리처럼 대규모 데이터를 실시간 처리할 수 있다.
내고장성 및 유지력: 카프카는 여러 브로커에 중복 데이터를 유지하며 고가용성을 제공한다. 데이터 복제를 통해 일부 브로커가 고장나도 다른 브로커에 있는 데이터를 컨슈머에게 제공한다. 또한, 설정을 통해 데이터를 유지할 기간을 정하여 데이터를 보관할 수 있다.
실시간 스트림 처리: 카프카의 실시간 데이터 스트림 처리 능력은 스파크, 스톰 같은 스트림 처리 프레임워크와 잘 어울린다. 이러한 프레임워크들은 데이터를 실시간 처리할 수 있어 복잡한 분석, 변환, 집계 등을 매우 빠르게 끝낼 수 있다.
통합 및 에코시스템: 카프카는 여러 커넥터, 라이브러리 등을 제공하여 다른 시스템이나 기술과 쉽게 통합할 수 있다. 데이터 소스와 싱크로 많이 사용되는 데이터베이스, 메세징 시스템과 클라우드 플랫폼에 대한 커넥터를 제공한다.
신뢰성 및 영구성: 카프카는 안정적인 메세지 전달을 보장한다. 카프카 토픽으로 발행된 메세지는 디스크에 보관되고 다수의 브로커들에 복제되어 데이터 손실을 방지한다. 메세지 손실이 용납될 수 없는 시나리오에 적합하다.
정리하면, 카프카의 확장성, 내고장성, 높은 처리율과 실시간 처리 기능은 전자 상거래, 주식, 통신 등에서 사용될 분산 스트리밍 애플리케이션, 마이크로서비스 아키텍처와 데이터 파이프라인 등의 개발에 용이하다.
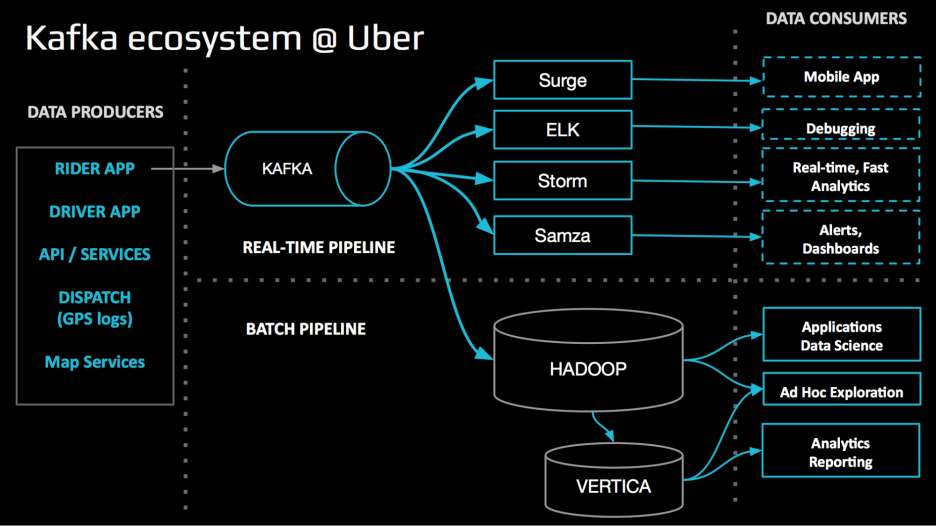
DB로 바로 보내지 굳이 카프카를 거쳐갈 필요가 있나?
데이터를 바로 데이터베이스로 보내어 DB로부터 데이터를 읽어 분석하는 방법도 가능하지만, 카프카를 중간에 두어 얻을 수 있는 이점도 있다.
탈동조화(Decoupling) 및 비동기 처리: 카프카는 데이터 발행자와 구독자 간 비동기, 분리된 통신을 가능케한다. 카프카를 메세지 큐로 사용하면 데이터 발행자들은 구독자의 상태/성능이나 데이터를 잘 받아서 처리했는지 신경 쓸 필요없이 데이터를 보내기만 하면 된다. 탈조동화를 통해 더 유연한 내고장성의 아키텍처를 제공하며 프로듀서와 컨슈머가 각자의 속도따라 동작할 수 있게 된다.
버퍼링: 프로듀서와 컨슈머 사이 버퍼 역할로 쏟아지는 데이터를 토픽들에 임시 보관하여 컨슈머는 자신의 속도따라 데이터를 받을 수 있다. DB로 바로 보내면 DB가 부하를 감당하지 못해 실패 또는 성능 이슈가 발생 가능하다.
데이터 통합 및 변환: 다양한 원천의 데이터를 통합/변환할 수 있다. 다양한 형태의 이종 데이터를 통합해야 할 경우 유용하다.
실시간 스트림 처리: 데이터가 도착하는 순간 바로 처리하므로 DB 저장까지 기다리는 낭비가 없다. 이는 실시간 분석, 모니터링, 의사결정에 유용하며 Spark, Flink 등의 스트림 프로세싱 프레임워크과 결합하여 복잡한 변환, 집계, 분석 등을 실시간 수행 가능하다.
데이터 복제 및 내고장성: 카프카의 분산 특성은 여러 브로커에 데이터를 복제하여 내고장성과 데이터 중복을 제공한다. 이로 인해 특정 브로커 또는 서버가 실패해도 데이터가 보존된다. 또한, 여러 컨슈머가 반복해서 동일 데이터를 읽을 수 있다.
이종 시스템 통합: 많은 시스템과 기술들에 대한 커넥터를 제공한다.커넥터를 통해 데이터베이스, 메세징 시스템, SNS, 클라우드 서비스 등으로부터 데이터를 간편하게 받을 수 있다. 즉, 다양한 데이터 소스 및 싱크들과 쉽게 통합할 수 있어 확장성이 뛰어난 아키텍처를 제공한다.
요약하면, 탈조동화, 버퍼링, 실시간 처리, 내고장성 및 통합 기능이 훌륭하므로 실시간 데이터 파이프라인과 스트리밍 애플리케이션에서 인기 있다.
프로듀서가 보낸 메세지가 카프카에 잘 도착했는지 어떻게 확신하지?
카프카 분산 특성 상(하드웨어 이슈, 소프트웨어 오류, 네트워크 실패 등) 완전히 보장하긴 매우 어렵지만 데이터 손실을 최소화하기 위해 제공되는 기능이 몇 가지 있다.
Acknowledgement Mechanisms: Customizable ack 메커니즘으로 메세지 영구성을 보장한다. 프로듀서는 메세지를 보내면 ack 모드로 0(ack X), 1(리더로부터 ack), all(리더가 복제들로부터 ack를 모음)를 정할 수 있다. "acks = all"로 설정한 경우, 메세지가 동기 복제된 후에 프로듀서에게 ack를 보낸다.
Replication Factor: 데이터를 몇 개로 복제하여 브로커들에 분산시킬지 결정하는 요인이다. 데이터 손실 위험을 줄인다.
Data Persistence: 데이터는 디스크에 보존되므로 브로커가 실패하거나 재시작되어도 잃지 않는다. 카프카는 디폴트로 일정 기간만 데이터를 보존하여 이미 처리된 데이터를 다시 읽을 수 있다. 유지 정책은 기간 또는 데이터 크기로 지정한다.
모니터링 및 알림: 카프카 클러스터의 상태를 주기적으로 점검한다. 메세지 처리율(Throughput), 레플리케이션 지연 및 브로커 상태를 점검하며 잠재적인 문제점을 발견하여 데이터 손실 위험을 줄일 수 있다.
정기적인 백업: 스냅샷 또는 외부 백업 솔루션을 활용하여 재난 및 데이터 변질/손실을 방지한다.
테스트 및 결함 주입 검증: 실패 시나리오를 재연하여 카프카 설정의 신뢰성을 검증한다. 브로커 실패, 네트워크 파티션처럼 다양한 실패 시나리오에서 시스템이 재구실할 수 있는지 점검 가능하다.
만일 카프카로부터 ack 메세지가 오지 않는다면?
메세지 전송이 너무 느리거나, 네트워크 문제가 있거나, 브로커가 고장났을 수 있다. 이런 경우, 프로듀서는 지정 타임아웃을 초과할 때까지 ack를 못 받으면 메세지 재전송, 로그 점검 등 애플리케이션에 따라 핸들링한다.
카프카 아키텍처는 어떻게 생겼나?

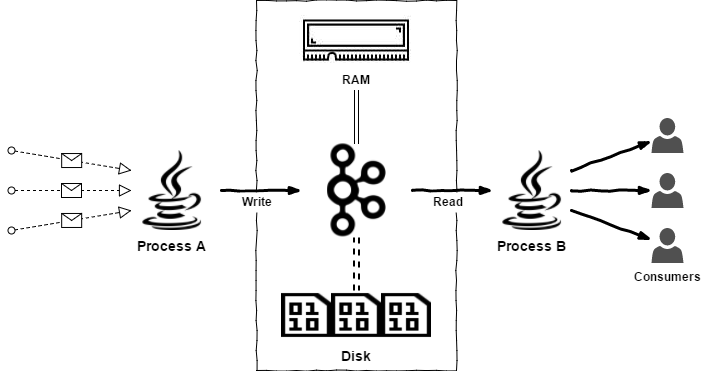
메세지를 받으면 디스크에 먼저 기록하나?
카프카는 메세지를 받는 즉시 디스크에 기록하지 않는다. 토픽에 메세지가 할당되면 먼저 write-ahead log(WAL) 또는 append-only log라는 메모리 상 자료구조에 기록한다. WAL에 메세지를 로그 끝에 순차적으로 기록하며 이는 카프카의 main 저장 구조이다. WAL은 파티션 별로 존재한다.
WAL에 메세지가 기록되면, 프로듀서에게 ack를 보내어 메세지를 받았음을 알린다. 그러나 이는 디스크에 기록됐음을 뜻하진 않는다.
카프카는 "batching" 기술로 disk write를 줄이고자 메세지를 batch로 모았다가 한꺼번에 디스크에 기록한다. 주기적으로 인-메모리 로그를 디스크로 flush하여 영구성을 보장하고, 블록 단위로 디스크에 순차적으로 쓰기(읽기도 빨라진다)를 요청하여 I/O 성능을 최대화한다.
정리하면, 카프카는 인메모리 버퍼링+batching+주기적인 disk flush로 성능 및 영구성 둘 다 보장하려고 한다. 데이터를 디스크에 기록하여 영구성을 제공하면서도 최적화된 디스크 I/O 연산으로 성능을 높인다. 메세지를 디스크에 일일히 기록하지 않아 ack를 빨리 보낼 수 있어서 프로듀서가 계속해서 메세지를 보낼 수 있다.
그럼 WAL에 있는 메세지를 컨슈머가 요청할 수 있나?
Replication을 포함하여 디스크에 기록되기 전까지는 읽을 수 없다. Leader Partition이 flush 전 데이터를 손실한다면 시스템 일관성이 깨진다.
카프카는 디스크에 기록된 메세지만 제공한다. 인메모리, 배칭 이 모든 기술은 오직 I/O 성능 최대화를 위할 뿐이다.
토픽과 파티션이 헷갈린다
먼저 이벤트, 스트림, 토픽의 정의와 관계를 이해하는 것이 필요하다.
이벤트
이벤트는 과거에 일어난 사실을 나타내며 여러 시스템을 이동하면서 불변의 특성을 지닌다.
스트림
프로듀서로부터 전송 받는 서로 연관된 이벤트들의 흐름이다. 시스템에서 발생한 이벤트들이 연속해서 들어오는 형태이다.
토픽
카프카에 이벤트 스트림이 진입하면 토픽으로 들어간다. 토픽은 이벤트 스트림이 물질화된 형태로 정적 스트림이라고 볼 수 있다.
토픽은 연관된 이벤트들을 모아 영구적으로 보존한다. 카프카의 토픽을 DB의 테이블이나 파일 시스템의 파일에 비유할 수 있다. 토픽을 활용하여 프로듀서와 컨슈머를 분리하고 각자의 속도에 쓰기(push) 및 읽기(pull) 연산을 수행한다.

파티션
토픽은 파티션으로 나눠진다. 토픽은 논리적인 개념이고 파티션은 토픽 내 레코드들의 부분 집합을 내포한 최소 저장 단위이다. 각 파티션은 단일 로그 파일로 존재하며 append-only 방식으로 레코드들을 기록한다. 메세지랑 레코드는 동의어이다.

오프셋과 메세지 정렬 상태
파티션 내 각 레코드는 오프셋이라는 고유한 숫자가 부여된다. 오프셋은 incremental & immutable 한 특성을 가진다. 레코드가 로그에 쓰일 때 마지막 레코드 다음의 오프셋 숫자가 부여된다. 오프셋은 보통 컨슈머가 파티션 내 레코드를 읽어갈 때 활용된다.
하단 이미지는 세 개의 파티션을 가진 토픽을 보여주며 레코드들의 로그의 끝 부분에 쌓여간다. 파티션 내 메세지들은 정렬된 상태이지만 파티션 간 메세지들은 어떤 순서를 갖지 않는다. 즉, 파티션 1 내 더 낮은 오프셋의 레코드가 파티션 2의 더 높은 오프셋의 레코드보다 먼저 발생한 메세지 또는 이벤트라는 보장이 없다. 전역적인 순서가 없다고 볼 수 있다.
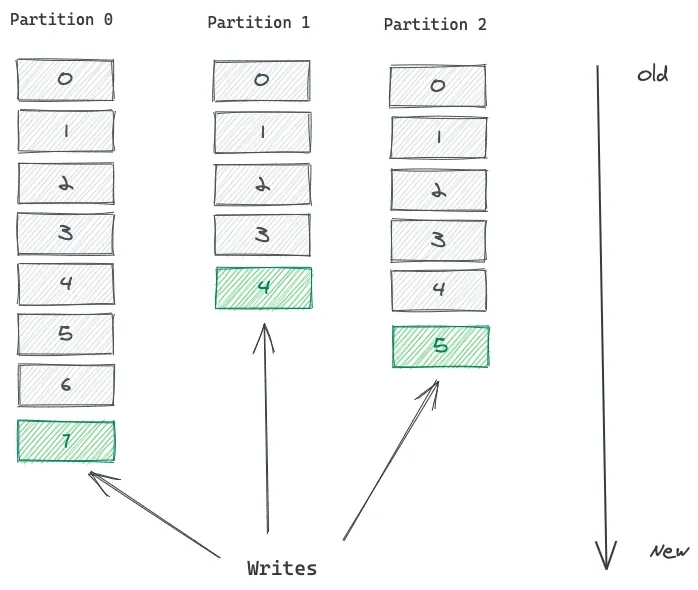
토픽은 여러 개의 파티션으로 분할된다. Kafka는 파티션을 통해 확장성을 제공한다.
카프카 클러스터는 한 개 이상의 서버 또는 브로커로 구성된다. 각 브로커는 레코드들의 부분 집합을 보관한다. 카프카는 한 토픽의 파티션들을 여러 브로커들에 분산시킨다. 이를 통해 다음 이점을 취할 수 있다.
단일 브로커에 모든 파티션을 넣으면 해당 브로커의 IO 성능에 따라 토픽의 확장성이 제한된다. 어떤 토픽도 클러스터 내 제일 큰 브로커보다 커질 수 없다. 다수의 브로커에 파티션을 분산시키는 수평적 확장이 성능 상 좋다.
단일 브로커가 한번에 처리할 수 있는 컨슈머들이 제한된다. 한 브로커에 중복 파티션이 없는 경우 컨슈머들이 동시에 이 파티션을 읽어가는 것이 제한된다. 컨슈머는 동시에 같은 파티션을 접근할 수 없다. 여러 브로커에 같은 파티션을 배치시키는 것이 병렬성이 좋다.
어느 파티션에 레코드를 쓸지 누가 결정하나?
프로듀서도 가능하고 카프카도 가능하다. 총 세 가지 방식으로 파티션을 결정할 수 있다.
먼저, 프로듀서가 파티션 키를 명시하여 메세지를 저장할 파티션을 결정할 수 있다. 파티션 키는 애플리케이션 단에서 임의로 정한 어떤 값도 괜찮다. 이유인즉슨, 같은 파티션 키를 가지면 반드시 같은 파티션에 할당되기 때문이다. 파티션 키는 해싱 함수를 거쳐 파티션을 배정한다. 연관된 이벤트들은 같은 파티션으로 보내져 정렬된 상태로 보관할 수 있다.

다만, 키 기반 파티션 할당은 메세지 할당의 불균형을 일으킬 수 있다. 예를 들어, 고객 ID를 파티션 키로 활용했을 때 한 고객이 90%의 트래픽을 일으킨다면 한 파티션에 90%의 트래픽이 몰린다. 스트림의 규모가 크다면 브로커가 고장날 수 있다. 따라서 파티션 키를 결정할 때 잘 분산될 수 있는 값으로 결정하는 것이 좋다.
또한, 파티션 개수가 변경된다면 메세지 키와 파티션 매칭이 달라지게 된다. 메세지 키가 null인 경우 UniformStickyPartitioner 또는 기본 설정 파티셔너에 따라서 파티션의 분배가 이루어진다. 참고 - https://blog.voidmainvoid.net/360
카프카 프로듀서는 레코드를 전송하기 위해 파티셔너를 제공합니다. 파티셔너 종류와 각 파티셔너에 대한 설명을 정리해보았습니다. 카프카 버젼이 올라감에 따라 파티셔너의 종류도 달라졌는데 여기서는 2.5.0 버젼의 파티셔너를 정리해보겠습니다. 프로듀서 파티셔너 인터페이스에 대한 설명은 아래 링크에서 확인할 수 있습니다. https://kafka.apache.org/25/javadoc/?org/apache/kafka/clients/producer/Partitioner.html kafka 2.5.0 API kafka.apache.org 메시...
blog.voidmainvoid.net
다음으로, 파티션을 명시하지 않고 카프카가 알아서 결정하게 둘 수 있다. 프로듀서가 레코드를 보낼 때 파티션 키를 명시하지 않았다면 카프카가 UniformStickyPartitioner 방식으로 메세지를 파티션에 배정한다. 따라서 메세지들이 파티션들에 고르게 분산될 것이다. 반면, 키가 필요한 경우는 연관된 이벤트들을 한 파티션에 보내어 이들의 순서를 정확하게 정렬할 필요가 있을 때이다.
마지막으로 커스텀 파티셔너를 직접 구현하여 파티션을 배정할 수 있다.
컨슈머는 파티션으로부터 어떻게 읽어오나?
일반적인 pub/sub 모델과 달리, 카프카는 컨슈머로 메세지를 push하지 않는다. 컨슈머가 파티션으로부터 읽어가야(pull) 한다. 컨슈머는 토픽, 파티션과 오프셋을 지정하여 메세지를 순서대로 읽는다. 여기서 메세지의 오프셋이 커서의 역할을 한다. 컨슈머는 오프셋을 참조하여 어디까지 읽었는지 분간한다. 메세지를 하나씩 읽을 때마다 컨슈머는 커서를 다음 오프셋으로 이동한다. 본래 오프셋은 Zookeeper라는 코디네이터에 저장했으나 현재는 카프카 내 "__consumer_offsets"라는 토픽에 저장한다. 컨슈머 측에서 오프셋을 관리하는 옵션도 있다고 한다.

하나의 파티션을 다수의 컨슈머가 저마다의 오프셋을 가지고 읽을 수 있다. 커밋에 관한 상세 내용은 다음 글을 추천한다.
https://ggop-n.tistory.com/90
컨슈머 그룹이 무엇인가?
컨슈머들이 모여 하나의 토픽만 읽는 논리적인 개념을 컨슈머 그룹이라고 한다. 같은 그룹에 있는 컨슈머는 전부 동일한 group-id 값을 가진다. 컨슈머 그룹은 하나의 메세지는 한번만 읽어가도록 보장하므로 동일 메세지를 중복으로 읽어가는 일이 없다. 각 파티션마다 컨슈머가 하나씩 배정되기 때문이다.
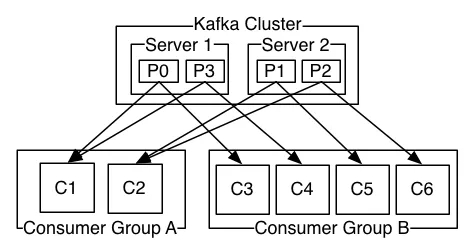
컨슈머 그룹을 통해 토픽의 메세지들을 병렬적으로 처리하므로 효율적이지만, 한 그룹의 병렬성은 토픽의 파티션 수만큼 최대화 되는 제한이 있다. 예로, N + 1 개의 컨슈머들이 N 개의 파티션이 존재하는 토픽을 처리하는 상황을 가정한다. 첫 N 개의 컨슈머들이 각각 파티션을 배정받고 나면 컨슈머 하나가 방치된다. 만일 N 개 중 한 개가 고장난다면 남는 컨슈머가 기존의 파티션으로 배정될 것이다. 여유 컨슈머를 두어 이런 상황을 모면할 수 있다.
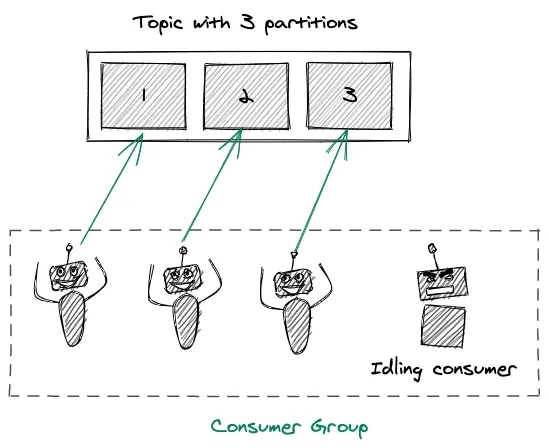
핵심은 토픽의 병렬성은 컨슈머 수가 아닌 파티션 수로 결정된다는 점이다.
적절한 컨슈머 수는 어떻게 결정하나?
컨슈머는 동적으로 추가할 수 있으므로 시작할 때 적게 시작하여 점차 늘릴 수 있다. 컨슈머 수는 다음 요인들을 참조하여 조정할 수 있다.
부하 및 처리율: 원하는 처리율이 있다면 메세지가 push 되는 속도와 컨슈머가 메세지를 처리하는 속도를 참조한다. 부하가 높고 메세지를 더 빨리 처리해야 한다면 컨슈머 수를 늘린다.
컨슈머 처리 속도: 컨슈머가 메세지를 처리하는데 드는 평균 시간을 계산하여 오래 걸린다면 컨슈머를 늘린다.
파티션 수: 컨슈머 수가 파티션 수보다 많다면 idle한 컨슈머가 생긴다. 한 컨슈머가 적절한 수의 파티션을 읽는 방식을 고려할 수 있다.
내고장성: 컨슈머가 고장나면 남는 컨슈머가 대체할 수 있도록 여유롭게 두는 것도 좋다.
컨슈머는 많을수록 컨슈머 그룹의 성능이 저하될 수 있다.
적절한 파티션 수는 어떻게 결정하나?

정답은 없으므로 유경험자들이 많이 쓰는 방법을 따라간다.
소수 X: 브로커와 컨슈머들에 파티션을 고르게 분배하기 어려워진다. 브로커들에 파티션을 고르게 분배하는 것이 어려우면 부하가 쏠리는 문제점이 생길 수 있고 컨슈머들에 파티션이 고르게 분배되지 못하면 일부 컨슈머만 consume을 많이하는 상황이 생긴다. 잘 나뉘는 숫자로 정하는게 좋다.
컨슈머와 브로커의 배수 값: 잘 나뉘는 숫자라는 건 브로커와 컨슈머에 고르게 분배될 수 있는 수일 것이다.
카프카 클러스터의 일관성: 두 토픽을 조인할 상황이 생겼는데 두 토픽의 파티션 수가 서로 다르면 Kakfa Streams가 토픽을 repartition 해야하며 이는 고비용의 연산이다.
목표 성능: 목표하는 성능(data throughput)이 있고 컨슈머와 프로듀서의 파티션 당 throughput을 안다면 필요한 파티션 수를 직접 계산할 수 있다. 데이터를 100 MB/s로 전송하는 것이 목표이며 프로듀서와 컨슈머의 파티션 당 throughput이 10 MB/s과 20 MB/s라면 최소 10개의 파티션이 필요하다. (컨슈머는 5개만 있어도 목표 성능이 가능하지만 프로듀서는 10개가 필요하다.)
토픽 설계 시 고려할 사항은 뭐가 있을까?
