* 프로젝트 요구 사항
성능 요구 -> 성능 결과 (소스 코드를 국제공인시험기관 '와이즈스톤'에서 검증)
Precision = 70% -> 73.3%
Recall = 65% -> 88%
F-Measure = 70% -> 80%
* 참고 자료
https://materialize.com/blog/kafka-is-not-a-database/
mapValues(_.length)는 각 원소 별로 occurence 횟수임.
https://azure.microsoft.com/ko-kr/resources/cloud-computing-dictionary/what-is-big-data-analytics
* 추가 필요
* 개인적으로 함수가 충분치 못하다고 느꼈음. 쉘로 개발하는데 리스트는 출력할 수 없고 데이터프레임으로 변환해야만 출력 가능한 점이나 리스트와 데이터프레임간에 변화해줘야 쓸 수 있는 함수 (collect) 같은 것들이 일부 있었음.
* Jar 파일로 만드는 부분도 복잡 -> 추가
* MongoDB 해킹 -> 추가
* 매뉴얼 작성 -> 추가
* 인코딩 - 디코딩 -> 추가
MongoDB랑 spark-shell에 연동 (mongo-spark-connector 패키지 사용)
package를 포함하여 package의 라이브러리들을 import
mongodb://127.0.0.1/cpmongo_distinct.USER_SIMILARITY (프로토콜://localhost/데이터베이스/컬렉션)
위를 변수에 넣고(val 변수명 = ""), getMongoDF(spark(=스파크세션), 컬렉션명)) 명령어로 컬렉션으로부터 DF 생성
filter는 조건을 만족하는 도큐먼트들만 걸러내기 위함.
- 기업 리스트 추출
N명 추출하기 위한 1단계 과정. 신청, 조회, 선배 취업 순(각 카테고리는 최신순으로 중요)으로 중요하게 본다. 선배 취업은 성별, 학과 전부 일치하는 학생이 취업한 기업만 포함. 특정 기업 개수를 채울 때까지 중요도 순으로 채워나감. 앞에서 채워지는 경우 이후 카테고리는 고려 대상에 미포함. 최종적인 기업 리스트 생성. 데이터로 존재하는 기업 수는 총 300개.
- 사용자 신뢰도
기업 리스트에 포함된 기업에 취업한 졸업생들을 filter해서 (졸업생 | 신뢰도) 데이터프레임을 만든다. 사용자는 특정 기업에 취업한 졸업생, 그리고 사용자 신뢰도는 기업 점수와 동일한 의미로 사용됨. 신뢰도는 해당 졸업생이 취업한 기업의 신뢰도를 가지고 계산하며 1. 기업 가중치와 2. 직원수 가중치에 추가적인 가중치를 각각 적용하여 합한 것이 사용자 신뢰도이다. 정보가 없는 기업은 0점 처리. 기업 점수는 아래와 같이 계산한다. w1,w2,a,b는 PM이 임의로 정해줌. a와 b는 기업가중치와 직원수가중치를 동일 scale로 맞추기 위해 사용. w1과 w2는 각 가중치의 중요도에 따라 정함. 그리고 활동 점수도 함께 고려함. 기업 점수와 활동 점수에 가중치를 적용하여 더한 값이 최종 사용자 신뢰도임.
▶ 기업 점수(add) = 기업가중치 * w1 * a + 직원수 가중치 * w2 * b
▶ 플랫폼 활동 점수(act_score) = 별점 개수(stars) / 수강 및 활동 개수(total)
out_act_score 리스트에 (학생 번호, 최종 점수)를 순차적으로 append
그렇게 사용자 최종 신뢰도 계산.
▶ 최종 사용자 신뢰도 = w1 * add + w2 * act_score
- 콘텐츠 신뢰도
콘텐츠 키, 평균 별점(agg)으로 묶음. 콘텐츠 신뢰도는 그냥 별점의 평균임.
- 유사도 계산
질의 학생과 가장 유사한 커리큘럼을 거친 학과 졸업생을 추천 리스트에 반영하기 위한 과정.
먼저 교과목, 비교과목, 대외활동 리스트를 만들어야 한다.
질의 학생의 수강 과목이랑 컴공과 전체 학생들의 수강 과목을 찾아내어 (학번 | [(교과목 코드, 별점)])으로 DF를 만들고 toMap으로 "학번 -> [(교과목 코드, 별점)]" 해시맵을 만듬.
757~954: 비교과에 대해서 만든 결과 Map(학번 -> Array(starPoint(키, 평점))
ex) Map(20142932 -> Array(starPoint(NCR_T01_P01_C03,null), starPoint(NCR_T01_P05_C02,null), starPoint(NCR_T01_P04_C03,3.8), starPoint(NCR_T01_P01_C01,4.5), starPoint(NCR_T01_P02_C03,3.85), starPoint(NCR_T01_P03_C03,4.0), starPoint(NCR_T01_P03_C01,4.2)), ...)
이후 대외 활동에 대해서도 비슷한 과정을 반복. 대외 활동에서는 자격증이랑 어학활동은 유무(1,0)을 기록하고 봉사/대외/기관은 각각 횟수를 계산한다.
이후 학번별 교과/비교과/자율활동을 조인하고 이를 mongodb의 user_list_for_similarity에 저장.
이렇게 만들어놓은 df로 코사인 유사도를 계산한다.
(전체 유사도 | 교과 유사도 | 비교과 유사도 | 대외활동 유사도)로 테이블을 구성한다. 이때 전체 유사도는 (교과목 유사도 * w1) + (비교과 유사도 * w2) + (대외활동 유사도 * w3)로 계산한다.
594~771: 아래처럼 만들려고 나눠진 테이블들을 필터 / 조인해서 중분류 별 평균 별점을 계산하도록 만듬. 원래는 (중분류 | 비교과키), (학번 | 비교과키 | 별점) 이런 식으로 나뉘어져 있던 걸로 보임. 이렇
Map(20142932 -> Array(starPoint(NCR_T01_P01_C03,null), starPoint(NCR_T01_P05_C02,null), starPoint(NCR_T01_P04_C03,3.8), starPoint(NCR_T01_P01_C01,4.5), starPoint(NCR_T01_P02_C03,3.85), starPoint(NCR_T01_P03_C03,4.0), starPoint(NCR_T01_P03_C01,4.2)),
비교과목 유사도 같은 경우도 학생의 중분류 별 평점을 가지고 유사도를 계산. 그냥 성향이 유사한 학생을 추천해주려는 이유인 듯.
자격증, 어학, 대외활동은 각각 존재 여부 그리고 횟수를 기준으로 유사도를 계산함. 순서는 코드 기준으로 정렬하는데 한 리스트에 병합하고(ex. (0, 1, 4, 1, 2)) 이걸로 유사도를 계산하는 듯. 대외는 크게 세 개로 구분되므로 세 개 각각의 코사인 유사도 값을 구하고 가중치를 적용해서 합한 게 유사도가 됨.
대외 활동은 유사도에서 빼는 게 좋음. 취준생한테 졸업생과 유사한 대외활동을 갖는게 유의미한지 모르겠음. 그냥 취준생이 들었던 교과, 비교과 리스트 한정해서 졸업생과 유사도를 계산해서 유사도 + 신뢰도 높은 졸업생의 대외활동을 추천해주는 게 더 말이 되는 듯.
* 추천 결과 생성
신뢰도랑 유사도랑 결합해서 N명의 추천 졸업생을 선정함. 이 N명을 기준으로 교과목, 비교과목, 자율 활동 추천 결과를 생성.
-졸업생 추천 결과
신뢰도랑 유사도에 보정 상수(a, b) 및 가중치 (w1, w2)를 적용해서 최종 점수 계산.
전체 평점 받은 횟수가 지나치게 적은 콘텐츠의 경우 추천 리스트에서 제외함.
-교과목 추천 결과
추천 졸업생의 교과목 수강 리스트를 모은 뒤 질의 학생이 이미 수강한 교과목은 제외함. 그리고 콘텐츠 신뢰도를 기준으로 랭킹해서 알려주는 듯. 여기에서 협업 필터링 사용.
-비교과목 추천 결과
교과목과 유사함. 여기에서 협업 필터링 사용.
-자율 활동
* 자격증과 어학은 개수에 따라 랭킹해서 이름으로 추천해줌.
* 봉사, 대외활동, 기관현장실습은 추천 졸업생의 평균 값을 계산해서 값을 반환
* 협업 필터링이 아닌, 단순히 선정된 N명의 졸업생들의 가장 많은 자격증 및 어학 + N명의 코드 별 평균 봉사, 대외, 실습 횟수로 보임.
최종 추천 결과는 (교과목 top 5 | 비교과목 top 5 | 자격증 top 5 | 어학 top 5 | 평균 봉사 활동 | 평균 대외활동 | 평균 기관현장 실습 횟수)임.
"협업 필터링 어떻게 설명할 건지 정리 필요"
- 코사인 유사도 수식
향하는 방향(각도)가 얼마나 유사한지를 비교한다고 볼 수 있음.
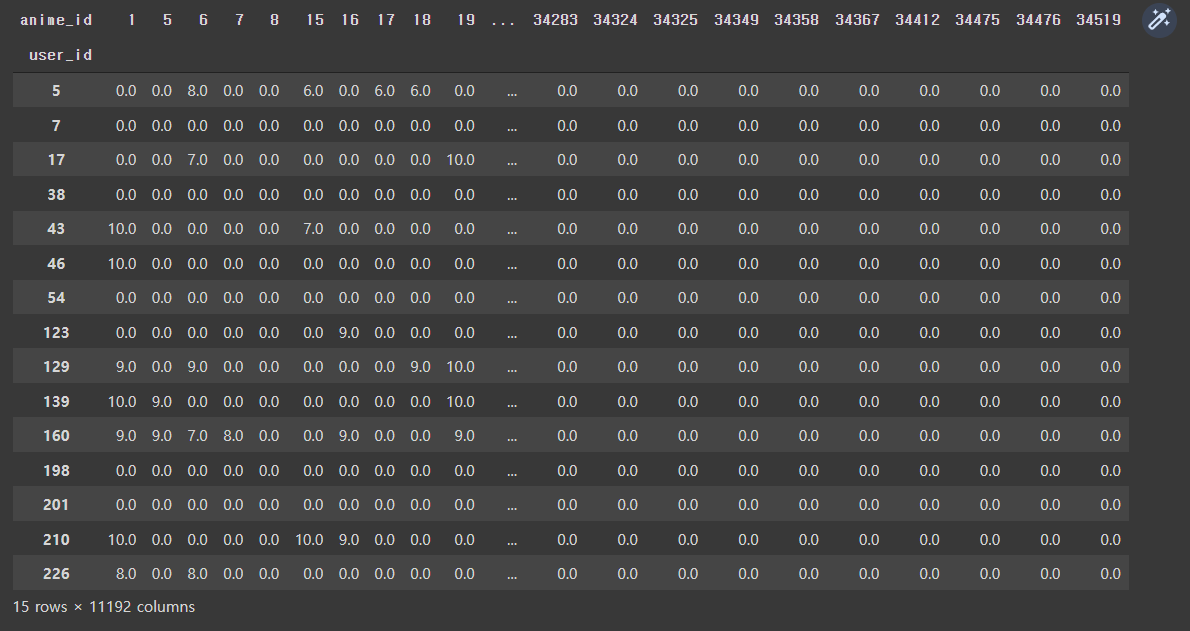
1. 피벗 테이블을 생성함. 아래는 예시임.
* 가능한 질문
Q: 왜 Python이 아니라 Scala를 썼나요?
A: Scala가 JVM을 사용해서 속도가 10배 빠르다. Python 인터프리터인 PyPy는 빌트인 JIT 컴파일러 사용. 대규모 데이터를 처리하는데 속도가 제일 큰 선택 요인으로 작용함. 또한 파이썬처럼 타입이 dynamically(런타임)에 결정되기 보다 statically(컴파일 타임)에 결정되므로 디버깅하는 것이 수월하다. Spark가 Scala로 만들어졌기 때문에 Scala를 쓰면 Spark의 더 많은 기능들을 활용할 수 있다는 이점도 참고되었음. 추가로 Scala 프로그래머가 Python 프로그래머보다 평균 연봉이 높다는 점도 기인함.
'R&D 프로젝트' 카테고리의 다른 글
| [R&D] MongoDB 해킹 방지 (0) | 2022.12.17 |
|---|---|
| [R&D] 프로듀서 (0) | 2022.12.17 |
| [R&D] 테이블 의미 (0) | 2022.12.17 |
| [R&D] 컨슈머 (0) | 2022.12.17 |

댓글